5 May 2020
Predicting Metrics With Neural Nets

Mirror, mirror on the wall, which user will buy the most stuff of them all?
Did you ever have to predict some kind of metric for user engagement, conversion rate, or something similar and wondered, how? No, you don’t need superpowers. Use the power of neural nets instead. The only other thing you need is data. The more, the merrier.
Let me demonstrate the basic idea by using a deep neural net to predict a score, in this case, the overall happiness score of a country, by just using a bunch of more or less related factors. Have a quick look at the data itself:
| GDP | Social support | Life Expectancy | Freedom of choice | Generosity | Corruption | Happiness Score | |
|---|---|---|---|---|---|---|---|
| Finland | 1.34 | 1.59 | 0.99 | 0.60 | 0.15 | 0.39 | 7.77 |
| Denmark | 1.38 | 1.57 | 1.00 | 0.59 | 0.25 | 0.41 | 7.60 |
| Norway | 1.49 | 1.58 | 1.03 | 0.60 | 0.27 | 0.34 | 7.55 |
| Iceland | 1.38 | 1.62 | 1.03 | 0.59 | 0.35 | 0.12 | 7.49 |
| Netherlands | 1.40 | 1.52 | 1.00 | 0.56 | 0.32 | 0.30 | 7.49 |
The dataset comes from the World Happiness Report and is freely available on Kagle.1 It includes different objective and subjective variables, like GDP, social support, or experienced generosity, for several countries, as well as the happiness score. The goal is to predict the happiness score, based on those variables which are sometimes called features in the realm of Machine Learning.
There are other approaches to achieve this (e.g. a multiple linear regression), but by applying a neural net, we can actually improve the accuracy of the prediction quite easily. And it’s much cooler.
Using the Power of Neural Nets
What is a deep neural net? Basically, it’s like a tiny, tiny model of a brain. You have interconnected neurons which fire on a given stimulus and produce an output signal. This abstract model consists of layers of neurons. We call it a deep neural net when it has multiple layers. The number of layers and neurons, as well as the inner mechanics of the simulated neurons and their connections to the other neurons, are only a few aspects of the complexity which have to be taken into account when building a neural net. Like our physical brains, it will slowly learn to produce the desired output when given an input. And, just like when you work out in a gym, training is actually the most time and resource-consuming process.
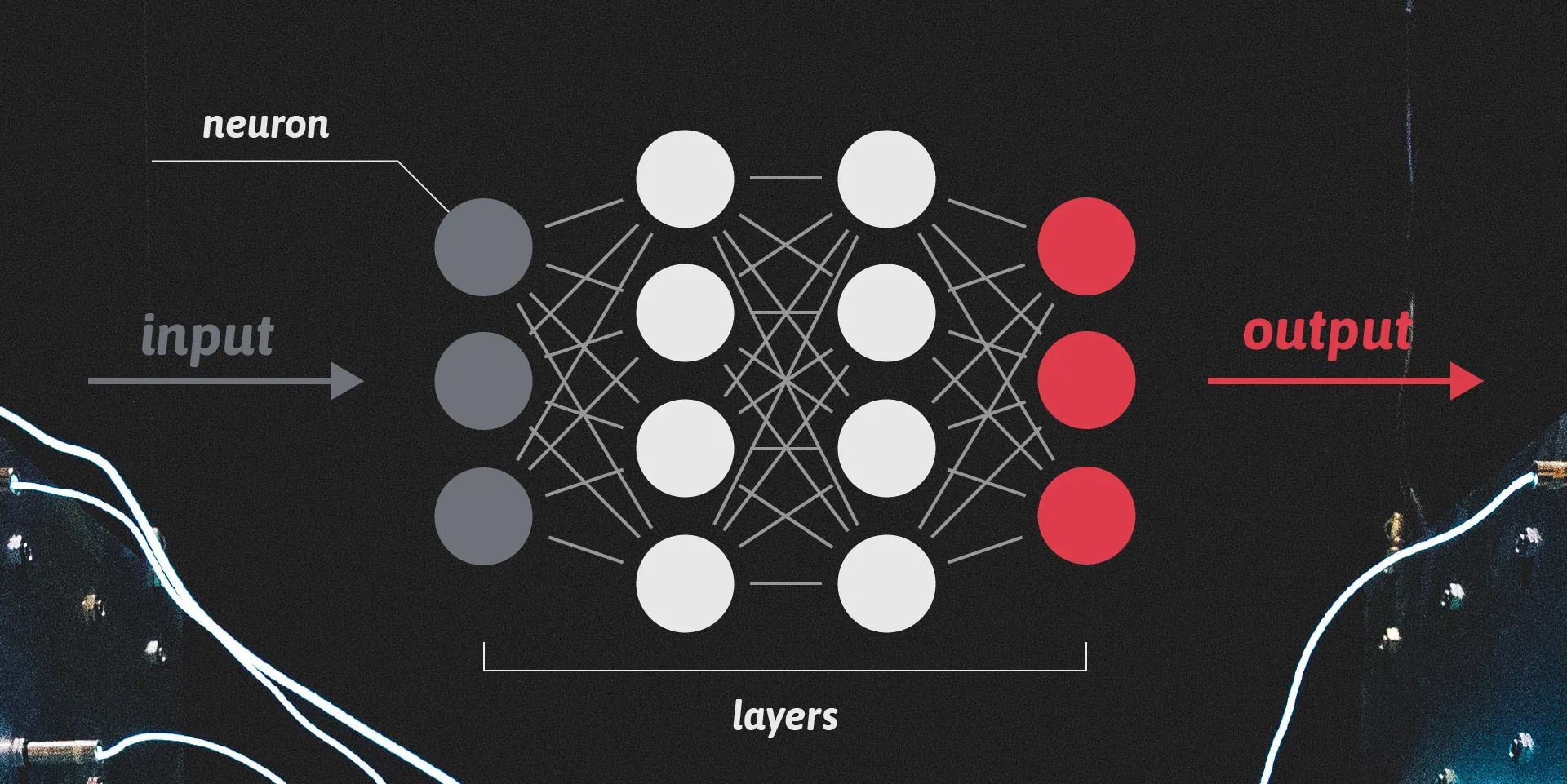
In our case, the input for the neural net would be all the features of the World Happiness Report dataset. The desired output is, of course, the happiness score. The neural net itself was quickly set up in Python using Google’s Tensorflow library. Due to the few data points, I only had to set up a small neural net. The hard part was finding the right parameters, i.e. the number of neurons, number of layers, and so on.
Hitting the Neural Gym
You can’t hit the gym without knowing what you want to achieve. You need a metric, perhaps your muscle mass or the number of crunches. Our goal is to guess the happiness score as precise as possible. Thus, we want to minimize the distance between the predicted score to the actual happiness score which we will call the error. The better the training the closer our predictions are on average for every score and the smaller the overall error. This will be our metric.
But not every training helps. If you use an ineffective workout, you won’t see much results. The success of training a neural net depends heavily on the chosen architecture, how you pre-process the data, and lots of tiny details.

Learning curves show us how well the training progresses over time. In the picture above you see the overall error of our predictions (the mean squared error) slowly decreasing with each training session. I guarantee you, it’s an unbelievably gratifying experience when you find a set of parameters which work! It’s the eureka moment because - depending on the amount of data, the complexity of your neural net and the hardware - each training can take minutes, hours, or even days.
Results
Let’s have a look at the results. In the plot below, you can see the predicted happiness score vs the actual happiness score for each country. When we predict it perfectly, all the points should lie on the diagonal. The further away from the diagonal, the greater the error.

What about the red dots? Those belong to a small, randomly taken sample called a validation set. Using all the available data could lead to an over-trained and rigid neural net. Instead, we want it to find the underlying hidden pattern which literally connects the dots. Using the validation set, we can assess how good our neural performs on unseen data.
For instance, Turkey had an actual happiness score of 5.37, while the predicted score was 5.29. On average, the deviation between the predicted and the actual happiness score within the validation set was 0.35.2 Considering the range of the ratings is 3 to 8, this is pretty good!
Using the Trained Neural Net
The trained net can now be used as an ordinary algorithm. Put in the factors of any given country and it will predict a very accurate happiness score for you. This can be done even on mobile devices because with a pre-trained net you don’t need all the heavy machinery anymore.
Using a neural net has another big advantage: Getting back to our example at the beginning about predicting the number of purchases, you can continuously train such a deep neural net. Just feed in the details about the purchase and the user, so that the net will reflect changes in behaviour and preferences of your user base.
Neural nets are here to stay. Thanks to a variety of products and frameworks out there, like Tensorflow, they can be implemented easily without having deep knowledge about the complicated math behind the scenes. Some services, like Azure or AWS, make it even easier to integrate Machine Learning into your existing product. But of course, that kind of gym membership comes with a price tag.
If you want to try it out yourself, feel free to download the Jupyter Notebook!